シリアライズされたページのワイヤフォーマット¶
Prestoは、ステージ間でデータ交換するために、シリアライズされたページバイナリ列形式を使用します。
データは圧縮、暗号化でき、チェックサムを含めることができます。レイアウトは、ヘッダー、複数の列、個々の列の順になります。

ヘッダー¶
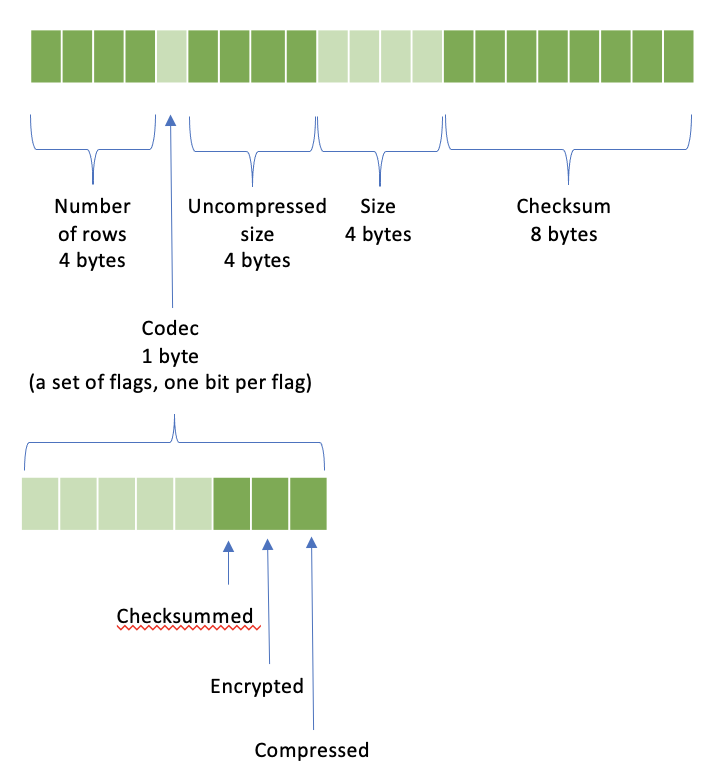
ヘッダーには以下が含まれます。
項目 |
サイズ |
|---|---|
行数 |
4バイト |
コーデック |
1バイト |
非圧縮サイズ |
4バイト |
サイズ |
4バイト |
チェックサム |
8バイト |
コーデックはフラグのセットであり、フラグごとに1ビットが設定されます。* 1ビット目が設定されている場合、データは圧縮されています * 2ビット目が設定されている場合、データは暗号化されています * 3ビット目が設定されている場合、チェックサムが含まれています
サイズは、ヘッダー後のペイロードのサイズです。データが圧縮されていない場合、サイズと非圧縮サイズは同じです。データが圧縮されている場合、サイズは圧縮データのサイズであり、非圧縮サイズは圧縮前のデータのサイズです。
チェックサムは、指定された順序で次のバイトについて計算されたCRC32です。* ヘッダー後のデータ * コーデック(1バイト) * 行数(4バイト) * 非圧縮サイズ(4バイト) コーデックにChecksummedビットが設定されていない場合、チェックサムは0でなければなりません。
注:列数はヘッダーの一部ではありません。ヘッダーの直後に4バイトで格納されます。
列¶
各列はヘッダーから始まります。データはその後に続きます。
列ヘッダー¶
列ヘッダーは、列のエンコーディングを指定します。
エンコーディング名の長さ - 4バイト
エンコーディングの名前
Presto型に対応するサポートされているエンコーディングとマッピングは以下のとおりです。
エンコーディング名 |
Presto型 |
|---|---|
BYTE_ARRAY |
BOOLEAN、TINYINT、UNKNOWN |
SHORT_ARRAY |
SMALLINT |
INT_ARRAY |
INTEGER、REAL |
LONG_ARRAY |
BIGINT、DOUBLE、TIMESTAMP |
INT128_ARRAY |
使用されていません |
VARIABLE_WIDTH |
VARCHAR、VARBINARY |
ARRAY |
ARRAY |
MAP |
MAP |
MAP_ELEMENT |
n/a |
ROW |
ROW |
DICTIONARY |
n/a |
RLE |
n/a |
presto-common/src/main/java/com/facebook/presto/common/block/BlockEncodingManager.javaを参照してください。
たとえば、INTEGER列のヘッダーはINT_ARRAYエンコーディングを記述します。エンコーディング名の長さは9であるため、最初の4バイトは0 0 0 9になります。次の9バイトにはINT_ARRAY文字列が格納されます。

NULLフラグ¶
すべての列には、1バイトのhas-nullsフラグが含まれます。0はNULLがないことを意味します。1はNULLがある可能性があることを意味します。has-nullsバイトが1の場合、個々のNULLフラグは、フラグごとに1ビットを使用して次のバイトで指定されます。0は値がNULLではないことを意味します。1は値がNULLであることを意味します。
Has-nullsフラグ - 1バイト
[オプション] NULLフラグ - 行数 / 8バイト; フラグごとに1ビット; ビットはバイトに逆順で格納されます; 各バイトの最初のフラグは最上位ビットです。
0ベースの行1、4、6、7、9に行にNULLがある10行があるとします。NULLフラグは3バイトで表されます。最初のバイトはhas-nullフラグ(1)を格納します。2番目のバイトは最初の8行のNULLフラグを格納します。3番目のバイトは最後の2行のNULLフラグを格納します。

XXX_ARRAYエンコーディング¶
BYTE_ARRAY、INT_ARRAY、SHORT_ARRAY、LONG_ARRAY、およびINT128_ARRAYエンコーディングは、値ごとに使用されるバイト数だけが異なります。
データレイアウトは以下のとおりです。
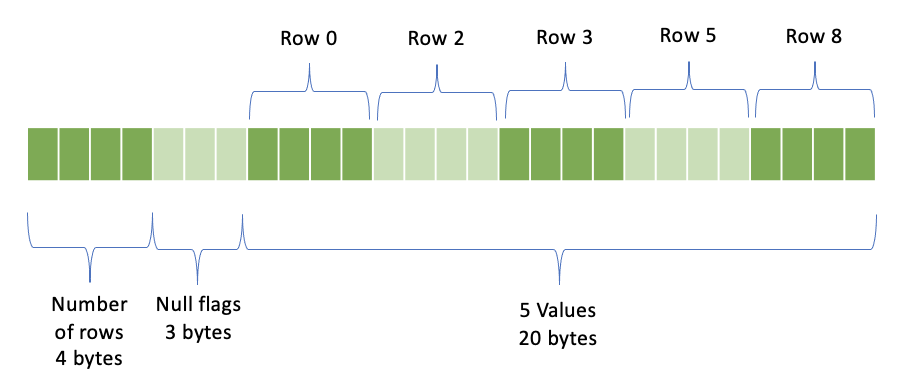
行数 - 4バイト
NULLフラグ
値 - (行数 - NULLの数)* <値ごとのバイト数>バイト; NULL以外の値を持つ行のみが表されます
値ごとのバイト数は以下のとおりです。
エンコーディング名 |
値ごとのバイト数 |
|---|---|
BYTE_ARRAY |
1 |
SHORT_ARRAY |
2 |
INT_ARRAY |
4 |
LONG_ARRAY |
8 |
INT128_ARRAY |
16 |
NULLフラグセクションの例を取り上げ、0ベースの行1、4、6、7、9に行にNULLがある10行の整数列があるとします。行数10を格納する4バイト、それに続く3バイトのNULLフラグ、それに続く行0、2、3、5、8の5つのNULL以外の整数値を表す20バイトがあります。
可変長幅エンコーディング¶
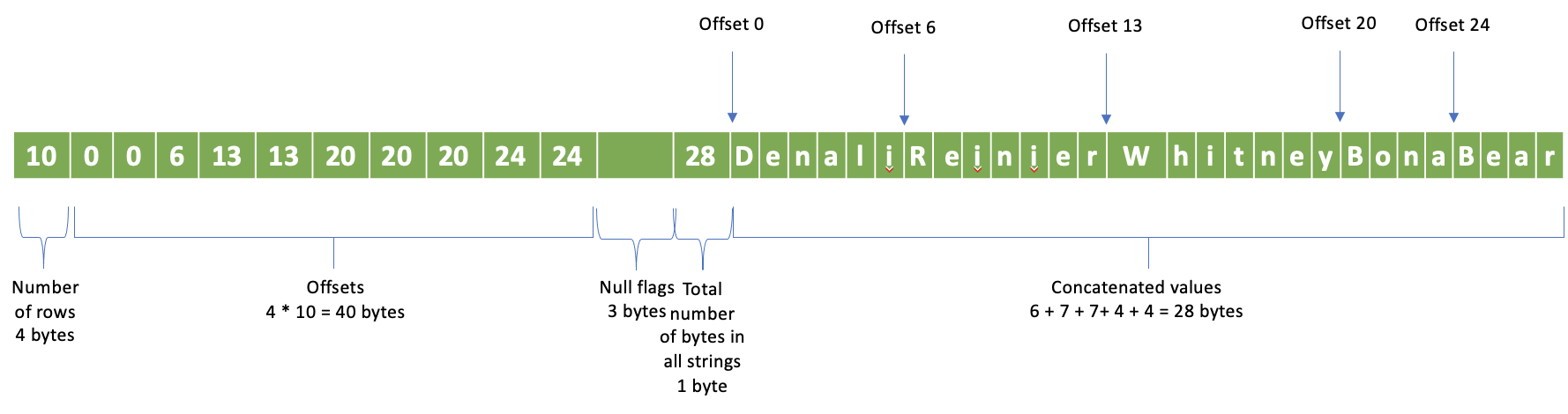
行数 - 4バイト
オフセット - 行数 * 4バイト; オフセットごとに4バイト
NULLフラグ
すべての値の総バイト数 - 4バイト
連結された値
再度、NULLフラグセクションの例を取り上げ、0ベースの行1、4、6、7、9に行にNULLがある10行の文字列列があるとします。NULL以外の行には、0 - Denali、2 - Reinier、3 - Whitney、5 - Bona、8 - Bearという値があります。行数10を格納する4バイト、それに続く40バイトのオフセット、それに続く3バイトのNULLフラグ、それに続くすべての文字列の合計サイズ1バイト(28)、それに続く連結された文字列値があります。NULL以外の行だけでなく、すべての行にオフセットがあることに注意してください。
ARRAYエンコーディング¶
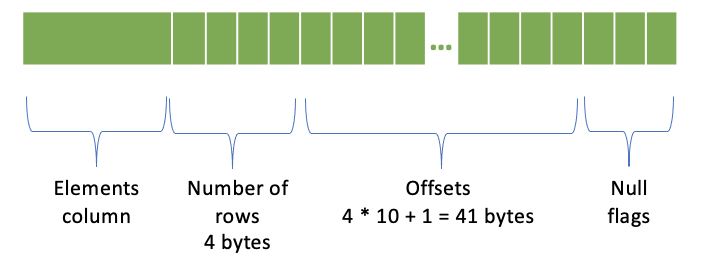
要素列
行数 - 4バイト
オフセット - (行数 + 1)* 4バイト; オフセットごとに4バイト
NULLフラグ
10行の配列列は次のように表されます。
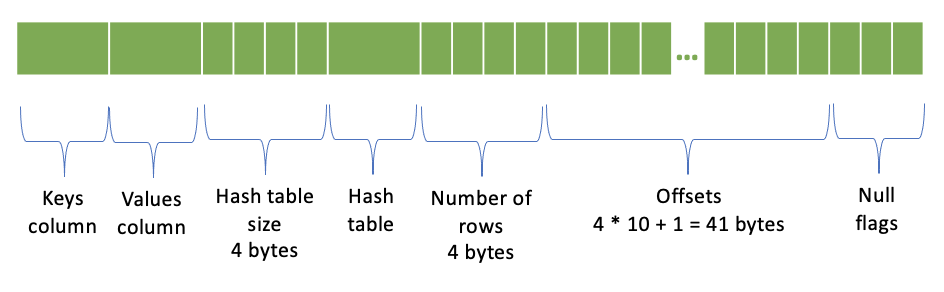
MAPエンコーディング¶
キー列
値列
ハッシュテーブルサイズ(ハッシュテーブル内の4バイトチャンクの数) - 4バイト
[オプション] ハッシュテーブル:<ハッシュテーブルサイズ> * <4バイト>
行数 - 4バイト
オフセット - (行数 + 1)* 4バイト; オフセットごとに4バイト
NULLフラグ
10行のマップ列は次のように表されます。
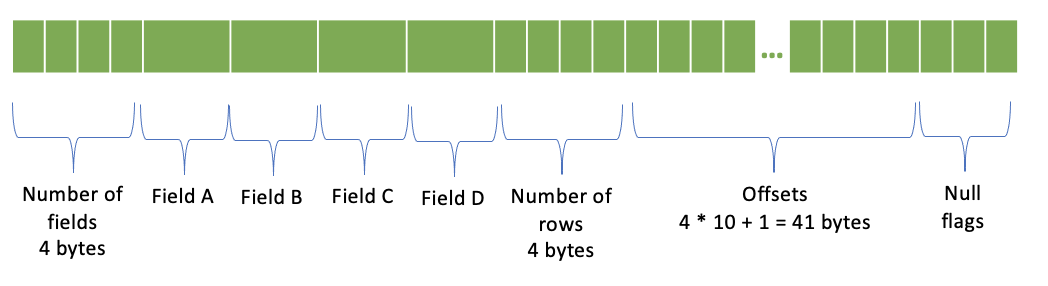
ROWエンコーディング¶
フィールド数 - 4バイト
フィールドごとに1つの列
行数 - 4バイト
オフセット - (行数 + 1)* 4バイト; オフセットごとに4バイト
NULLフラグ
ネストされた列は、NULL以外の行に対してのみシリアライズされます。NULL行が存在する場合、ネストされた列の行番号は最上位レベルの行番号と一致しません。オフセットはネストされた列の行番号を指定しています。
再度、NULLフラグセクションの例を取り上げ、0ベースの行1、4、6、7、9に行にNULLがある10行のROW(a、b、c、d)型の列があるとします。ネストされた列は5行のみになり、オフセットは0、0、1、2、0、3、0、0、4、0になります。NULL行のオフセットは0です。
注:オフセットは、NULLフラグから再構築できるため、冗長な情報です。
DICTIONARYエンコーディング¶
行数 - 4バイト
辞書値列。この列自体は、このドキュメントで説明されているエンコーディングのいずれかのエンコーディングを持つシリアライズされたブロックです。
インデックス - 行数 * 4バイト; インデックスごとに4バイト
辞書ID - 24バイト
RLEエンコーディング¶
行数 - 4バイト
単一行定数値列
追加の使用法¶
SerializedPage形式は、CoordinatorからWorkerへ送信されるプランフラグメント内の定数値を指定するためにも使用されます。この場合、バイナリ表現はBase64エンコーディングを使用してASCII文字列に変換されます。
例えば、`SELECT array[1, 23, 456]` クエリに対するプランには、`array[1, 23, 456]` の値をSerializedPage形式のバイナリをBase64エンコードした形で表現したProjectノードが含まれています。
- Project[projectLocality = LOCAL] => [expr:array(integer)]
Estimates: {rows: 1 (51B), cpu: 51.00, memory: 0.00, network: 0.00}
expr := [Block: position count: 3; size: 92 bytes]
また、セッションプロパティ`exchange_materialization_strategy`が`ALL`で、`temporary_table_storage_format`が`PAGEFILE`の場合、中間データを保存するためにもこの形式が使用されます。